


부스팅(Boosting)
부스팅은 약한 학습기(weak learner)를 순차적으로 학습시켜 강한 학습기(strong learner)를 만드는 방법이다.
1. 순차적인 학습 :
부스팅은 이전 학습기의 오차에 집중하여 다음 학습기를 학습시키는 과정을 반복한다.
초기에는 전체 학습 데이터셋을 사용하여 첫 번째 모델을 학습시킨다. 그 후, 첫 번째 모델이 잘못 예측한 샘플에 가중치를 부여하여 다음 모델을 학습시킨다. 이렇게 순차적으로 모델을 학습시키면서 이전 모델의 오차를 보정해 나간다.
이러한 방식으로 약한 학습기들을 조합하여 강한 학습기를 만들어낸다.
2. 가중치 업데이트 :
부스팅에서는 각 학습기에 가중치를 부여하여 오차에 대한 보정을 진행한다.
오차가 큰 샘플에 더 큰 가중치를 부여하여 다음 모델이 이를 보완하도록 유도한다. 이렇게 샘플에 가중치를 부여하고 가중치를 업데이트하는 방식은 약한 학습기들이 집중적으로 학습할 부분을 조절하며 예측 성능을 향상시킨다.
3. 예측 결과 결합 :
각 학습기가 개별적으로 예측한 결과를 결합하여 최종 예측을 수행한다. 일반적으로는 가중합(weighted sum)을 사용하여 예측 결과를 결합한다. 가중합을 통해 각 모델의 예측 결과에 가중치를 부여하여 최종 예측을 도출한다.
이러한 방식으로 여러 모델의 예측을 종합함으로써 예측의 정확도를 향상시킨다.
대표적인 알고리즘 :
AdaBoost : 가중치를 업데이트하며 순차적으로 학습
Gradient Boost(XGBoost, LightGBM) : 오차 함수의 경사(gradient)를 이용하여 순차적으로 학습
배깅(Bagging)
배깅은 병렬 학습과 랜덤 샘플링을 통해 다수의 예측 모델을 만들고 그 결과를 집계하여 최종 예측 수행하는 기법이다.
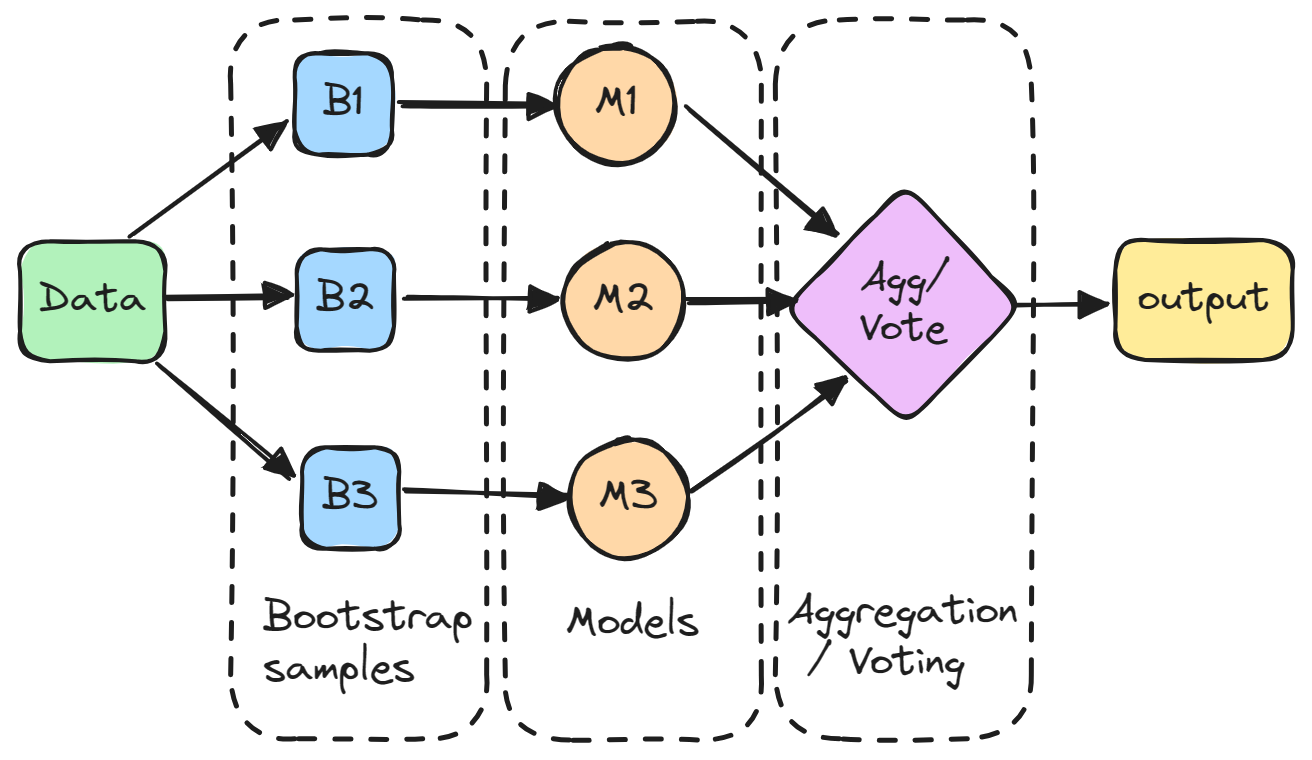
1. 랜덤 샘플링(bootstrap) :
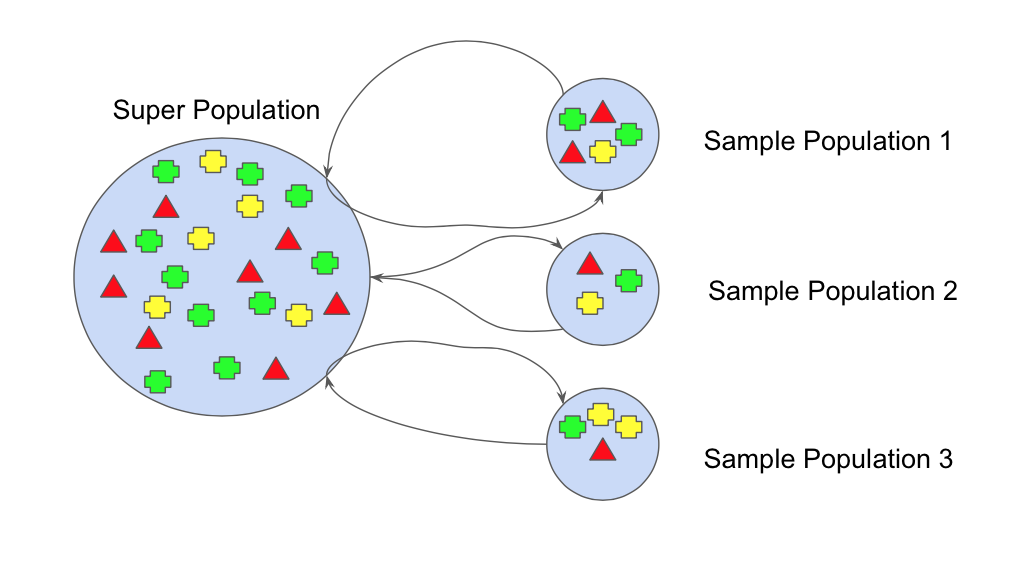
원본 데이터셋에서 랜덤하게 중복을 허용하여 샘플을 선택한다. 이를 통해 각 모델이 서로 다른 데이터셋으로 학습되므로,
다양성을 확보할 수 있다. 다양한 데이터 샘플링을 통해 각 모델은 조금씩 다른 관측치와 속성을 학습하게 되어
예측의 안정성과 성능을 향상시킬 수 있다.
2. 병렬 학습 :
다수의 예측 모델을 동시에 병렬로 학습.
각 모델은 독립적으로 학습되기 때문에, 복잡한 모델의 학습에도 효율적으로 대응 가능.
3. 예측 결과 집계 :
다수의 모델이 개별적으로 예측한 결과를 집계하여 최종 예측 수행.
일반적으로 분류 문제에서는 투표(voting) 방식을 사용하고, 회귀 문제에서는 평균을 계산하여 예측 결과를 도출.
대표적인 알고리즘 :
랜덤 포레스트 : 의사결정 트리 기반 알고리즘 -> 배깅의 개념을 적용하여 다수의 의사결정 트리를 학습하고 예측 결과를 집계
두 방법의 차이 요약 :
1. 학습 방식 :
부스팅 : 순차적으로 약한 학습기를 학습시키고 이전 학습기의 오차를 보완해 나가는 방식
배깅 : 독립적으로 다수의 학습기를 병렬로 학습시키는 방식
2. 데이터 샘플링 :
부스팅 : 이전 학습기에서 잘못 예측한 데이터에 가중치를 부여하여 다음 학습기에 사용
배깅 : 랜덤 샘플링을 통해 서로 다른 데이터셋을 생성하여 각 모델에 사용
3. 예측 결과 집계 방식 :
부스팅 : 각 학습기의 예측을 가중합하여 최종 예측을 수행
배깅 : 다수의 모델이 예측한 결과를 투표 또는 평균을 통해 집계하여 최종 예측 수행
요약하면, 부스팅은 순차적인 학습과 오차 보정에 초점을 두며
배깅은 병렬 학습과 다양성을 통한 안정성 향상에 초점을 둔다.
배깅의 랜덤 샘플링 방식 (bootstrap)
'데이터 분석 > MLDL' 카테고리의 다른 글
| 시계열 예측 모델 (맛보기) (2) | 2024.03.06 |
|---|---|
| K-Means(K-평균) 알고리즘 (3) | 2024.02.28 |
| Feature Selection에 대해 (0) | 2024.02.13 |
| [머신러닝 기초] 분류 모델 평가 지표 등등 (1) | 2024.02.08 |
| 선형회귀 연습 (0) | 2024.01.30 |