
# 현재 상황
# 8월 2주 차 개강반부터 새로 제작된 3주차 콘텐츠를 듣기 시작했습니다.
# 8월 중순부터 웹개발 종합반의 완주율이 크게 떨어진 이유를 밝혀야 합니다
# 8월 중순부터 웹개발 종합반의 완주율이 크게 떨어졌으므로,
# 비슷한 시기에 진행한 프로덕트 개선이 영향을 미쳤을 가능성이 있어보입니다
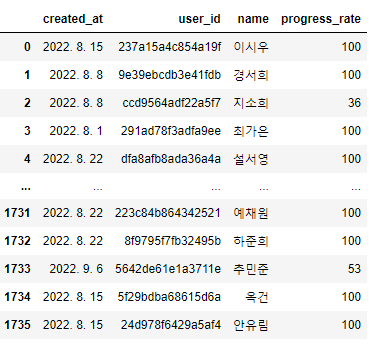
.
우선 데이터는 이런 모습을 가지고 있다.
각각의 개강반(주차)별로 진도율(주차)을 구해서 히트맵을 그려보자.

일단 created_at 컬럼이 문자열이라 datetime 형식으로 바꿔주었다.
포맷을 지정해 주고 pd.to_datetime을 통해 datetime 형식으로 바꿔주고
개강반을 의미하는 start_week 컬럼을 만들어 넣어주었다.
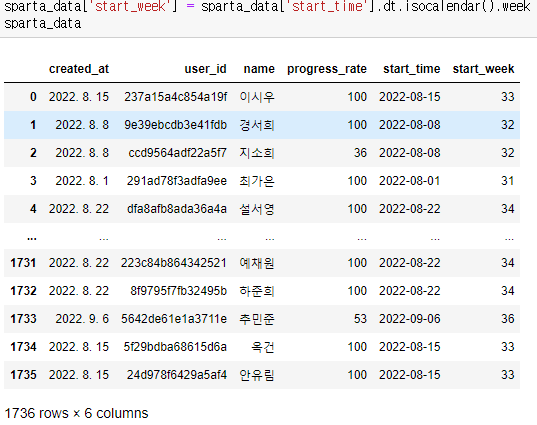
위 사진처럼 개강한 주를 알기 위해 dt.isocalendar().week를 이용하여
개강한 주를 나타내는 컬럼을 만들었다.
year, day 도 사용이 가능하다.
특정 수강생이 "어느 주차에" 머물러 있는지 알기 위해 진도율은 만져보자
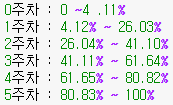
0~100 각각의 진도율을 범주화하기 위해 필요한 정보이다.
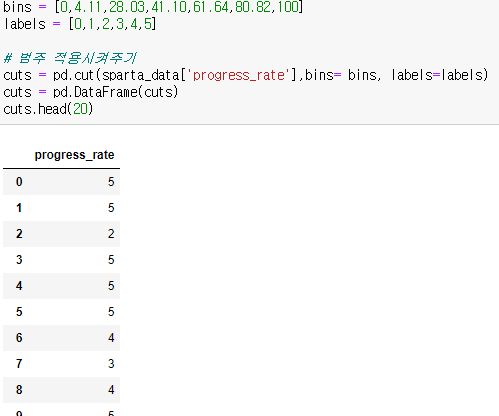
각각의 주차별 범위를 bins에 넣어주고 label 에는 0~5주 차를 넣어주었다.
그리고 pd.cut을 이용하여 범주 데이터를 적용시켜주었다.
마지막으로 그 데이터를 DataFrame 형식으로 바꿔주기

그리고 진도율(몇 주차에 머무르고 있는지)을 나타내는 cut와
기존의 sparta_data를 병합해 주었다.

그리고 편의를 위해 맨 마지막의 progress_rate 컬럼을 week로 이름을 바꿔주었다.
여기서 컬럼명을 바꿀 때는 테이블의 컬럼 수에 맞게 다 명시해 주어야 하며
sparta_data.columns[6]="weeks"이런 식으로 하면 오류가 난다.

위 테이블을 개강 주(start_week)와 진도율(week) 를 기준으로 묶어주었다.
테이블을 보면 달라진 게 없어 보이지만 아래쪽 로우와 컬럼의 수를 보면 묶여진 게 보인다.

수강 시작 주와 수강 주차에 각 해당하는 수강생의 수를 구해주었다.
이렇게 각 주차별로 머물러 있는 수강생 수를 구했지만
우리에게 필요한 것은 각 주차별 강의를 완료한 학생 수다.
5주에 머물러 있다면 1,2,3,4 주 차도 완강을 했겠지?
그래서 그것을 구하려면
k = 31
for i in range(6):
for j in range(5,0,-1):
cohort_data.at[(k,j-1],'user_id') =
cohort_data.at[(k,j),'user_id'] + cohort_data.at[(k,j-1),'user_id']
k = k + 1이런 과정을 거쳐야 한다.
변수 k는 시작 주(start_week)를 의미하고 31주차가 첫 시작 주니 k = 31
그리고 총 31,32,33,34,35,36 의 시작 주를 가지고 있으니 i 의 range 는 6을 줬다.
그리고 그 안에서 또 for문을 돌리는데 j는 머무르고 있는 주(week)를 의미한다.
0주 차부터 5주 차까지 있으니 j는 5부터 0까지 -1씩 감소시켜줬다.
그래서 흐름을 요약하면 5주 차부터 시작해서 j에 5가 들어가면
4(j-1)주차 = 5주차 + 4(j-1)주차 이런 흐름이다.
0주차까지 다 하게 되면 k를 1 증가 시켜서 다음 start_week로 가서 똑같은 행위를 반복한다.
여기서 at 함수는 테이블의 하나의 요소에 접근할 수 있게 해주는 함수이다.
전처리 과정은 끝이고 피벗 테이블을 만들고 히트맵을 그려주면 끝!

피벗 테이블을 만들어주었다.
인덱스는 시작주를 넣고 컬럼에는 머무르고 있는 주 밸류에는 user_id 값을 넣어줬다.
하지만 생각해 보니 단순하게 인원수만 이용해서는 비교하기가 힘들다.
각 개강 주차 별로 전체 수강 인원이 다르기 때문이다.
해결책은 비율을 구해주면 된다.

리텐션 테이블을 만들어주면 된다.
앞서 만든 피벗 테이블을 retention 변수에 저장해 주고
각 주(week) 별로 최초 수강생의 수만 가져와 주었다.
그리고 .divde를 이용하여 앞에서 가져온 최초 수강생의 수를 표의 데이터들을 나누어 주었다.
그러면 0.97827382 이런 식으로 나오게 되는데
round(3) * 100을 통하여 세 자릿수에서 반올림하고 * 100을 해주었다.
이제 마지막으로 히트맵을 그려주자

data에는 들어갈 데이터를 넣어주면 되고 다른 요소들은 그때그때 필요에 맞게 조정해 주자.

결과
변경된 3주차 커리큘럼이 수강 완주율에 영향을 미쳤을거라 생각했지만
전체적으로 완주율이 떨어지는 것을 확인할 수 있다.
아마 완주율에 영향을 미친 다른 요인이 있지 않을까?
'데이터 분석 > python' 카테고리의 다른 글
| 파이썬 Scipy 활용 (1) | 2024.02.27 |
|---|---|
| [python] 캐글 설문조사 Q1~Q6 (1) | 2023.12.26 |
| [3주차 숙제] 가장 많은 수강생들의 수강이 완료되는 시점을 알아내기 (0) | 2023.12.12 |
| 상관계수 구하기, 그래프 그리기 (0) | 2023.12.11 |